

When NVIDIA unveiled Blackwell at NVIDIA GTC, it didn’t just introduce a new GPU architecture. It triggered an economic shock for enterprise AI.
According to NVIDIA’s latest data, Blackwell delivers nearly 2× higher FLOPS per dollar than Hopper. However, more importantly it achieves 34× lower cost per million tokens and up to 64× higher token output per GPU.
This represents a fundamental shift in how AI infrastructure translates into real business value, making the gap not incremental but existential for AI profitability at scale.
This article breaks down why cost per token is now the dominant KPI for AI infrastructure decisions, what NVIDIA’s “inference iceberg” reveals, and how you should rethink your infrastructure strategy before your competitors do.
The Inference Iceberg: Why FLOPS Is Only the Tip
NVIDIA’s framing of the “Inference Iceberg” is one of the most important conceptual shifts in enterprise AI infrastructure.
At the surface, you see:
- FLOPS.
- GPU specs.
- Peak throughput.
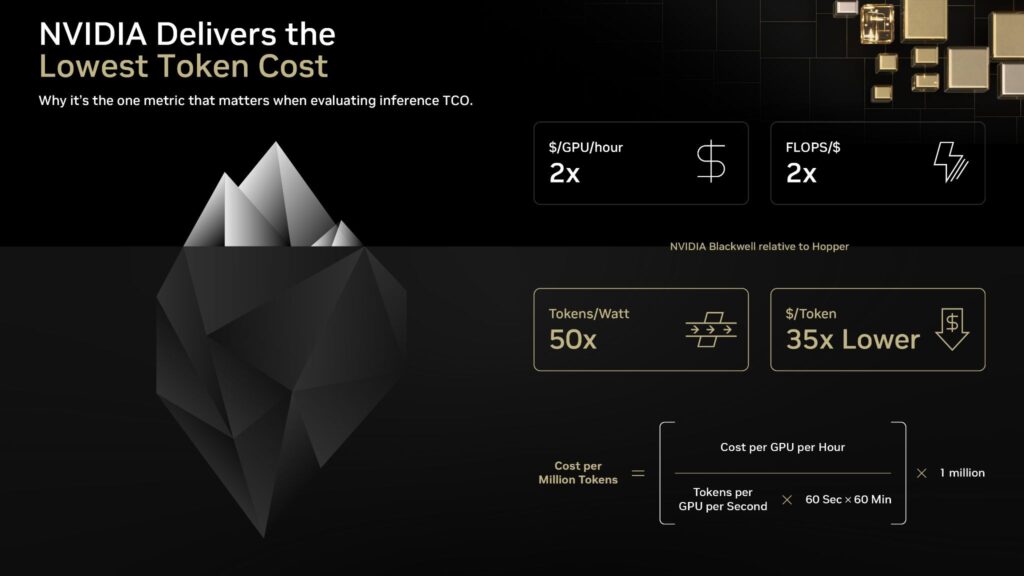
Below the surface. where real business impact lives:
- Token throughput under real workloads.
- Memory bandwidth constraints.
- Model optimization efficiency.
- Power and cooling costs.
- Latency under concurrency.
- Cost per token.
The Problem
FLOPS per dollar measures potential compute. It does not measure delivered business output.
In production inference environments:
- Models are memory-bound, not compute-bound.
- Batch sizes fluctuate.
- Latency constraints limit theoretical utilization.
- Token generation efficiency becomes the bottleneck.
This is why two GPUs with similar FLOPS can produce orders of magnitude differences in cost per token.
The Wake-Up Call
If your procurement team is still benchmarking GPUs using FLOPS per dollar, you are effectively optimizing for a metric that:
- Does not map to revenue.
- Does not reflect user experience.
- Does not capture operational cost.
As Jensen Huang has repeatedly emphasized in recent keynotes, “the goal is no longer just faster computing. It is delivering more useful work per unit of energy and cost.”
The Data Behind the Shift: What Blackwell Changes
Let’s translate NVIDIA’s claims into enterprise-relevant metrics.
Table 1. GPU Performance vs Real Inference Output
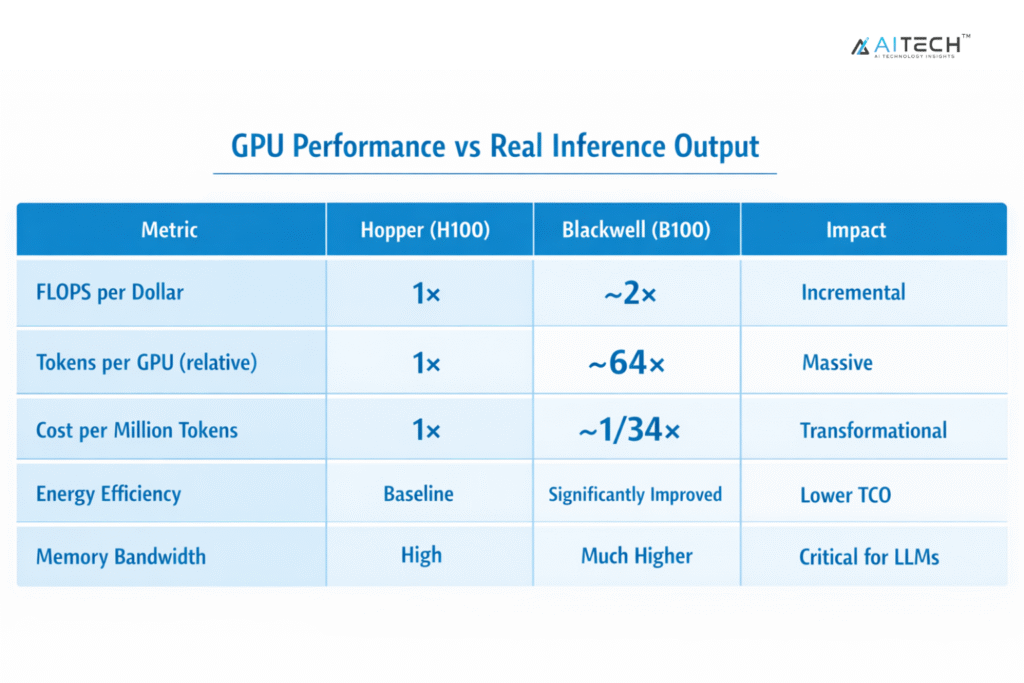
Implication
If your current system generates tokens at $0.01 per 1K tokens:
- On Hopper: $10 per million tokens.
- On Blackwell: potentially <$0.30 per million tokens.
Now scale that:
- 100M tokens/day → $1M/month vs $30K/month.
- 1B tokens/day → $10M/month vs $300K/month.
This is not a performance upgrade. It is a business model shift.
External Benchmarks: The Industry Already Knows This
NVIDIA’s claims align with broader industry findings.
1. Gartner
Inference is becoming the leading factor driving the need for infrastructure for AI, with over half of optimized infrastructure being used for inference purposes by 2026, according to Gartner.
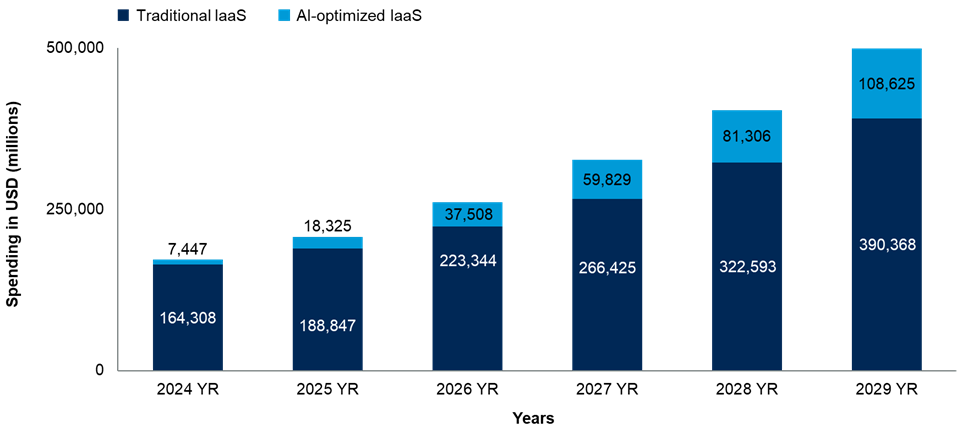
This exemplifies an ongoing trend in the industry as well as one that suggests that organizations should focus more on practical factors than on performance.
“Traditional IaaS is maturing, however, AI-optimized IaaS spending growth projections are higher than that of traditional IaaS over the next five years,” said Hardeep Singh, Principal Analyst at Gartner.
2. McKinsey & Company
As reported by McKinsey & Company in its paper titled “The cost of compute: A $7 trillion race to scale data centers,” AI infrastructure spending is reaching a level that is unprecedented in history.
The global demand for data center capacity is set to increase threefold by 2030, with about 70 percent of this increase resulting from the demands of AI workloads.
To meet this growing demand, organizations will have to spend up to $6.7 trillion on data center infrastructure, with an estimated $5.2 trillion on AI compute.
3. Bloomberg
As Bloomberg reports, the performance and cost associated with AI infrastructure are now heavily dependent on constraints at a system level involving GPUs, memory, power, and even data center limitations.
It is further evidence that the performance of AI in real-life situations is dependent on the whole stack.
Why Cost Per Token Defines AI Profitability
Let’s bring this down to business impact.
Example: Enterprise Customer Support AI
Assume:
- 5M customer interactions/month
- 1,000 tokens per interaction
That’s 5 billion tokens per month.
Scenario A: Legacy (Hopper-like economics)
- $10 per million tokens
- Monthly cost: $50M
Scenario B. Blackwell-like economics
- $0.30 per million tokens
- Monthly cost: $1.5M
Difference: $48.5M/month
That delta determines whether your AI initiative scales, your margins survive, and if your competitors undercut you.
AI Factories: Inference as the New Battleground
Not only has AI progressed beyond training-based experiments and pilots, but it also now encompasses continuous inference at scale that helps run critical operations and deliver value by generating revenues.
The rise of inference-dominant enterprise workloads, such as enterprise-level assistants, retrieval augmented generation systems, agentic AI architecture, real-time fraud detection, and decision-making engines, is driving this shift.
The mentioned workloads are not intermittent and periodic in nature. Instead, they operate continuously, in real-time, and at a very large scale.
One thing that ties all these workloads together is their reliance on inference. These workloads are designed to operate with low latency as they involve user interactions, as well as incur high costs, as each token they generate increases their costs.
As a consequence, efficiency in terms of inference has become the new battleground.
Looking Ahead: What’s Next for 2026?
What we are witnessing is only the beginning of a more fundamental shift in the way that AI hardware is conceived, procured, and tuned.
Ultra Blackwell and Beyond
With an eye on the future, next-generation AI infrastructure will continue the trend of striving for even more efficient token usage rather than mere computational improvements.
As evidenced by the roadmap from NVIDIA presented during NVIDIA GTC, specialization in inference will continue, with the design of memory bandwidth, interconnect capability, and overall efficiency taking priority.
In addition, greater integration of hardware and software will occur with framework development being paired with silicon development.
Custom Silicon Competition
The hyperscalers, along with large companies, are ramping up their efforts toward designing specialized inference chips for their unique workload requirements.
Examples of such initiatives include Google’s TPUs, Amazon’s Inferentia, and Microsoft’s Maia, which are optimized based on performance/watt and cost/token instead of general-purpose computation.
This represents a major transition in competitive strategies as companies focus more on workload-efficiency infrastructure, whereby competing on compute will no longer be the primary factor but rather the ability to maximize efficiency in converting compute to output.
IDC Forecast (2026)
Enterprise AI spending trends, according to IDC, indicate a rapid move from training towards inference as companies progress beyond initial pilot programs into broader production rollouts.
It expects that the majority of enterprise AI spend will go towards inference-based workloads, emphasizing the rising value of on-the-fly AI systems and ongoing model deployment.
This will bring about changes in procurement strategy, with cost per token and efficiency per workload becoming common metrics of evaluation.
“The rise of GenAI and AI agents is transforming a once-linear stack into a dynamic ecosystem, reshaping infrastructure demand and redefining roles across the tech landscape,” said Deepika Giri, head of research, Asia/Pacific.
Consequently, evaluation of AI compute resources will become more akin to evaluating cloud pricing options, whereby efficiency measures and scalability will become far more important than pure hardware capabilities.
Conclusion
The world of AI has moved away from training towards inference, and the cost of producing one token will become the deciding factor when it comes to efficiency and profitability.
NVIDIA Blackwell data clearly shows that the key to success in the field of AI is now not how much compute power you possess, but how well you are able to harness this power into tokens at minimal expense.
Organizations that do not adopt their infrastructure strategy according to the changing market landscape will find themselves forced into expensive systems that hinder both growth and innovation.
For the next phase of enterprise AI, the economic viability of operations will depend on how well tokens are produced. Organizations that take note of this trend will not only lower their expenses, but they will also create new possibilities altogether.
Want to quantify your AI inference costs?
Download our AI Inference TCO Calculator or book a consultation.
FAQs
1. Why has the cost per token become the main indicator for choosing AI infrastructure?
It shows the actual cost of using AI in production and represents the real cost-efficiency of operations.
2. What difference will NVIDIA Blackwell bring to business AI?
This platform increases tokens generated per dollar, improving the efficiency and cost-effectiveness of AI solutions.
3. Which factors influence the highest expenses in production-level AI systems?
Focusing on inference costs, memory bandwidth, energy consumption, and efficient use of GPUs.
4. What is the problem with current AI metrics based on FLOPS?
Those benchmarks assess only theoretical capabilities and cannot reflect the actual cost-efficiency.
5. How can enterprises adjust their AI infrastructure strategy in 2026?
Focusing on token-based KPIs and real-world metrics for AI.
Discover the future of AI, one insight at a time – stay informed, stay ahead with AI Tech Insights.
To share your insights, please write to us at info@intentamplify.com





