

The most effective AI systems in production today share a quiet advantage. They are not smarter models, but faster listeners, built to absorb real-time AI data as it’s generated, not hours or days later. They act on live signals. Customer intent. Security anomalies. Operational drift.
That shift, from retrospective intelligence to real-time decisioning, is reshaping how modern enterprises think about data infrastructure. In 2026, real-time data pipelines are no longer a performance upgrade. They are the difference between AI that informs and AI that intervenes.
More than 80 percent of data leaders now say streaming data platforms are essential to achieving AI outcomes, and organizations using real-time pipelines report materially higher returns from AI investments within the first year (Confluent Data Streaming Report 2025)
Data in motion has become the raw material for trust, relevance, and risk mitigation. And the systems that move it now sit squarely in the line of business accountability.
Why Batch Thinking Quietly Undermines AI Value
Batch architectures were built for a different era. They excel at reconciliation, reporting, and compliance. They assume delay is acceptable and errors can be corrected after the fact. AI breaks those assumptions.
Fraud detection models trained on hourly aggregates miss attacks that unfold in minutes. Security analytics fed by delayed telemetry produce alerts after damage is done. Customer personalization engines driven by overnight updates react to behavior that has already shifted.
The contradiction many enterprises face is uncomfortable. They are deploying AI to enable real-time decisions, while still feeding those systems with slow, fragmented data.
Gartner has warned that by 2026, organizations that fail to modernize AI data ingestion and governance will experience twice the rate of AI-related security and compliance incidents compared to peers that do.
During the Gartner Data & Analytics Summit in Sydney, Carlie Idoine, VP Analyst at Gartner, said, “Nearly everything today – from the way we work to how we make decisions – is directly or indirectly influenced by AI. But it doesn’t deliver value on its own – AI needs to be tightly aligned with data, analytics and governance to enable intelligent, adaptive decisions and actions across the organization.”
The constraint is not tooling availability. It is architectural intent.
Event Streaming as the AI Nervous System
Most scalable real-time AI architectures converge on event streaming as their foundation. The common requirement is not a specific product, but a capability. The ability to ingest, persist, order, and replay streams of events reliably, at scale, across distributed systems.
Apache Kafka is often used to meet this requirement because its log-based design supports continuous consumption while preserving rewind and reprocessing. That capability is essential for production AI. Models must be retrained. Decisions must be auditable. Regulators increasingly require traceability across automated systems. None of this works if the data is treated as transient once delivered.
At the same time, Kafka is not the architecture itself. It represents one implementation of a broader streaming pattern that also includes managed platforms, cloud-native services, and emerging abstractions designed to reduce operational complexity. What matters is not the technology choice, but whether the system provides durable event history, deterministic ordering, and verifiable lineage under load.
This is where many organizations misjudge the role of event streaming. It is often framed as a messaging infrastructure. In reality, any system that feeds real-time AI becomes part of the decision record. Once AI outcomes depend on streaming inputs, the stream itself becomes part of the risk, governance, and accountability surface.
The Trade-Offs Leaders Tend to Underestimate
Real-time pipelines are not just faster batch systems. They shift where risk accumulates.
Speed versus Data Quality
Streaming architectures magnify errors instantly. A single malformed event can cascade through models in seconds, not days.
Control versus Operational Burden
Self-managed platforms offer governance depth but demand maturity that many teams underestimate. Managed services reduce toil, but introduce cost opacity and dependency trade-offs that only surface at scale.
Latency versus Governance
Under pressure to reduce milliseconds, teams often bypass validation and policy checks. That shortcut holds until AI outputs are challenged. When that happens, missing lineage becomes a liability.
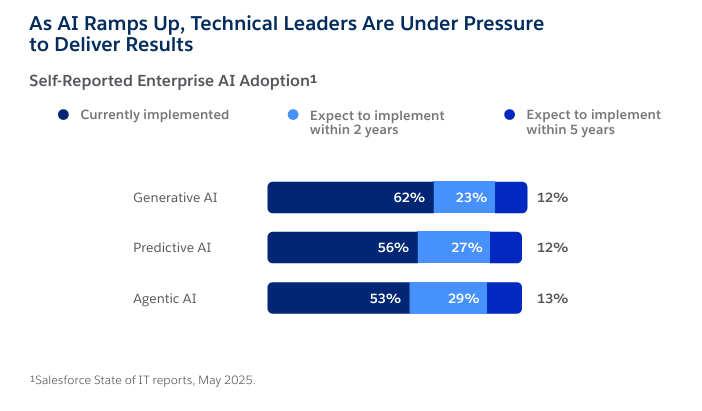
Salesforce research shows that nearly 30 percent of enterprise data used for analytics and AI remains unreliable, directly eroding model performance and trust (Salesforce State of Data and Analytics 2025).
The Cost of Speed Without Governance
Consider a global retail platform rolling out real-time personalization across web and mobile. Clickstream events stream directly into recommendation models with sub-second latency.
In week one, engagement lifts. In week three, complaints spike. Customers receive repeated offers for products they already purchased or explicitly dismissed minutes earlier. The root cause is not the model. It’s the stream.
A minor schema change in one regional event producer silently altered how “intent” was classified. The change propagated instantly across models. No validation gate caught it. No lineage view traced recommendations back to specific events.
The system kept running. Decisions kept firing. Trust eroded faster than any batch system would have allowed.
What Actually Scales in 2026
Organizations scaling real-time AI successfully treat pipelines as socio-technical systems, not just infrastructure stacks.
They formalize data contracts between producers and consumers. Schema evolution is governed as rigorously as API versioning. Observability extends beyond system health into business outcomes, tracing model decisions back to individual events.
Governance is embedded directly into streaming workflows. Encryption, access control, and policy enforcement travel with the data while it moves, not after it lands. Emerging research shows that stream-first governance materially reduces downstream AI errors and retraining costs compared to post-hoc controls (arXiv)
This discipline slows early experimentation slightly. It accelerates everything that follows.
AI Tech Insights Analysis
From our analysis, real-time AI pipelines rarely fail for technical reasons. The tooling is mature. The failure pattern is organizational.
Real-time removes the margin for ambiguity that batch systems quietly tolerate. When data moves continuously, every unresolved question surfaces immediately.
Who owns the event? Which version of truth applies?
What level of confidence is acceptable before an automated decision fires? Streaming architectures do not create these gaps. They expose them.
This is why many AI programs stall after early success. Models perform well in controlled environments, then degrade once connected to live data. Schema drift accelerates model drift. Latency optimizations bypass governance. Responsibility fragments across teams that were never designed to operate at machine speed. The system keeps running. Trust erodes.
The impact is most visible in customer-facing AI. Real-time personalization trained on inconsistent or weakly governed streams tends to overreact. It interprets noise as intent. Messaging misfires. Experiences feel abrupt rather than relevant. Salesforce data confirms the consequence. Customers are nearly three times more likely to disengage when personalization feels mistimed or inaccurate, even when intent is sound (Salesforce State of Marketing 2025)
Security teams see the same pattern from a different angle. Streaming telemetry feeds automated detection and response systems. When signal quality degrades, AI-driven defenses either hesitate or overcorrect. Both outcomes increase risk. Faster data does not compensate for unclear ownership or weak lineage. It amplifies the damage.
FAQs
1. Why is real-time AI data critical for enterprise decision-making in 2026?
Because AI systems increasingly drive live decisions, not reports. Real-time AI data enables organizations to act on current signals instead of outdated snapshots, improving accuracy in security response, personalization, and operational control.
2. How do real-time data pipelines improve AI performance at scale?
They reduce latency between data creation and model action, minimize stale inputs, and support continuous retraining and validation. This allows AI models to stay aligned with changing behavior and conditions in production environments.
3. What role does Apache Kafka play in real-time AI data pipelines?
Apache Kafka acts as a durable event-streaming backbone that moves, stores, and replays real-time data reliably. This enables scalable ingestion, low-latency processing, and traceability required for production AI systems.
4. What are the biggest risks of using poorly governed real-time AI data?
Poor governance amplifies errors at speed. Inconsistent schemas, unclear ownership, or low-quality signals can quickly lead to model drift, compliance exposure, security blind spots, and customer trust erosion.
5. How should CISOs and CMOs approach real-time AI data strategy differently in 2026?
Both should treat real-time data pipelines as decision infrastructure. CISOs must focus on signal integrity and security enforcement in motion, while CMOs must ensure real-time data quality to avoid misfiring personalization and brand damage.
Discover the future of AI, one insight at a time – stay informed, stay ahead with AI Tech Insights.
To share your insights, please write to us at info@intentamplify.com





